High Collinearity Effect in Regressions

Collinearity refers to the situation in which two or more predictor variables collinearity are closely related to one another. The presence of collinearity can pose problems in the regression context, since it can be difficult to separate out the individual effects of collinear variables on the response.
This R Notebook seeks to ilustrate some of the difficulties that can be result from a collinearity.
Collinearity
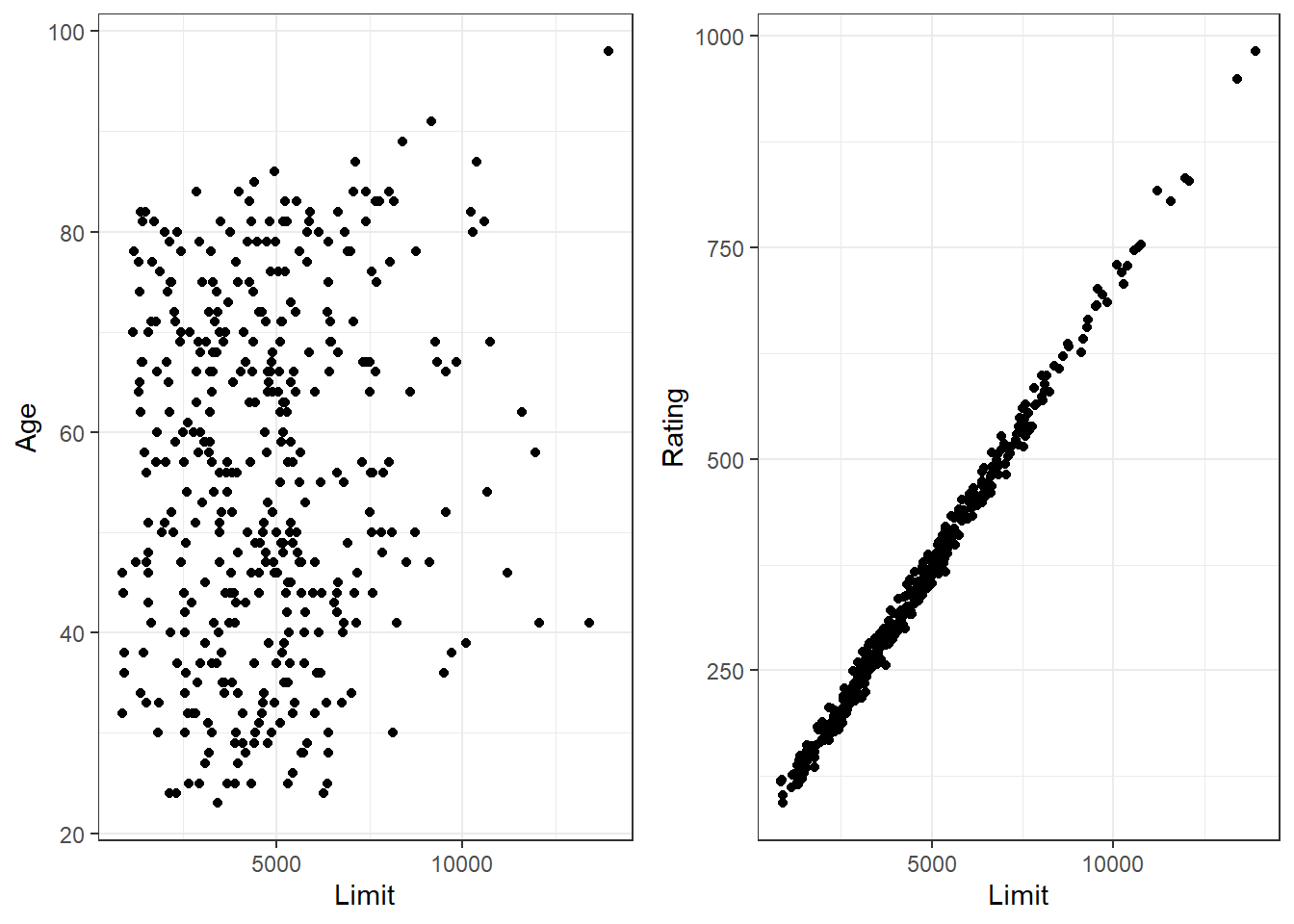
The concept of collinearity is illustrated in Figure below using the Credit data set in the ISLR Package. In the left-hand panel of Figure the two predictors limit and age appear to have no obvious relationship. In contrast, in the right-hand panel the predictors limit and rating are very highly correlated with each other, and we say that they are collinear.1
|
|
Effect on a Model
Let’s fit two models using these pair of features (age x limit and Rating x Limit) to predict the Balance outcome and see what happen with the model performances
|
|
|
|
The first is a regression of balance on age and limit, here both age and limit are highly significant with very small p-values.
|
|
|
|
In the second, the collinearity between limit and rating has caused the standard error for the limit coefficient estimate to increase by a factor of 12 and the p-value to increase to 0.701. In other words, the importance of the limit variable has been masked due to the presence of collinearity.
Collinearity reduces the accuracy of the estimates of the regression coefficients, it causes the standard error for $ \hat{ \beta } _{j} $ to grow. Recall that the t-statistic for each predictor is calculated by dividing $ \hat{ \beta } _{j} $ by its standard error. Consequently, collinearity results in a decline in the t-statistic. As a result, in the presence of collinearity, we may fail to reject $ H0 : \beta _{j} = 0 $ . This means that the power of the hypothesis test-the probability of correctly power detecting a non-zero coefficient-is reduced by collinearity.
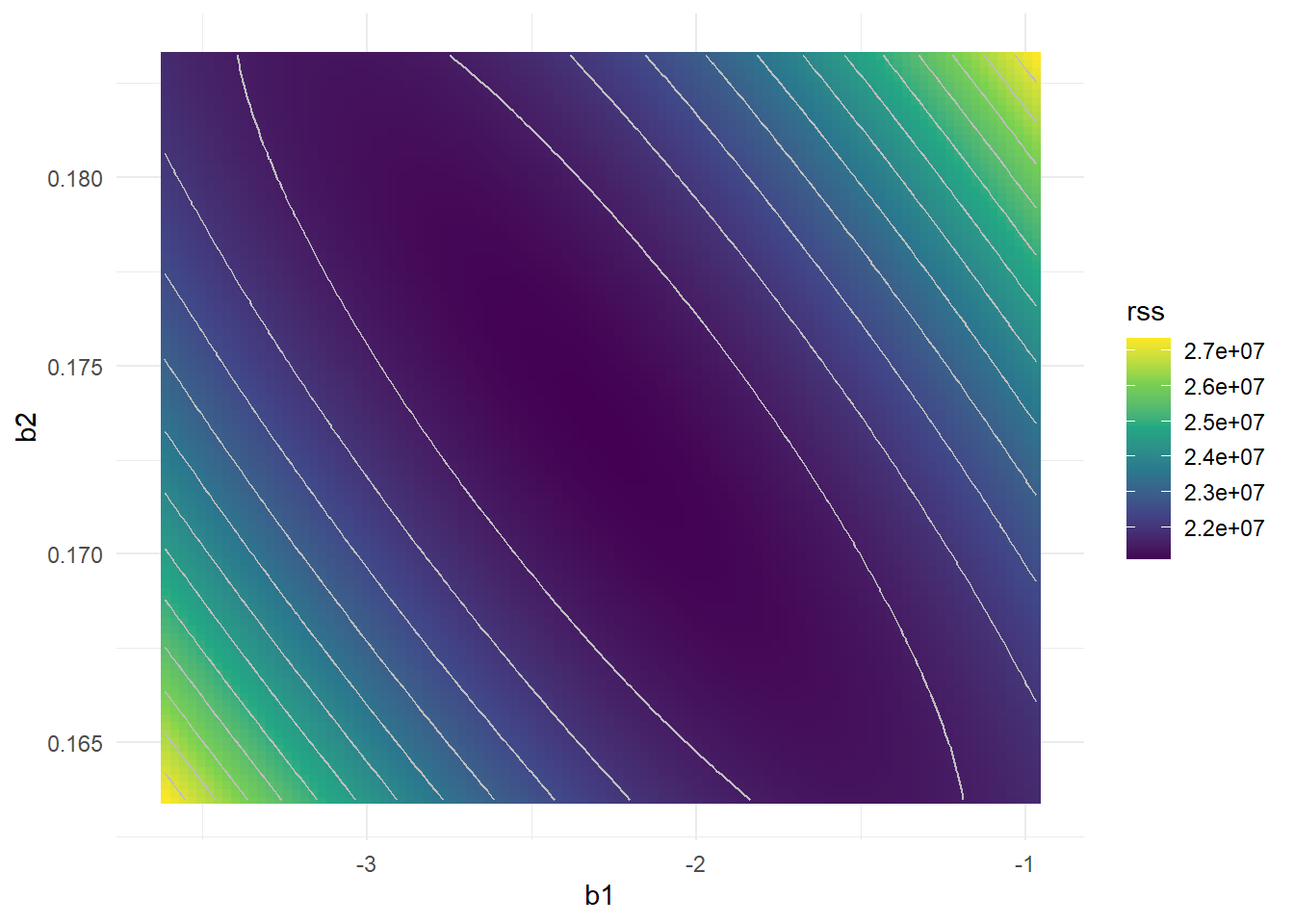
Cost Surface
Why the collinearity reduces the accuracy of the regression coefficients? What is the effect of it in the fitting model? To visualize the effect lets plot the Cost Function surface (RSS) in the space of the coefficents.
Age x Limit
|
|
Rating x Limit
|
|
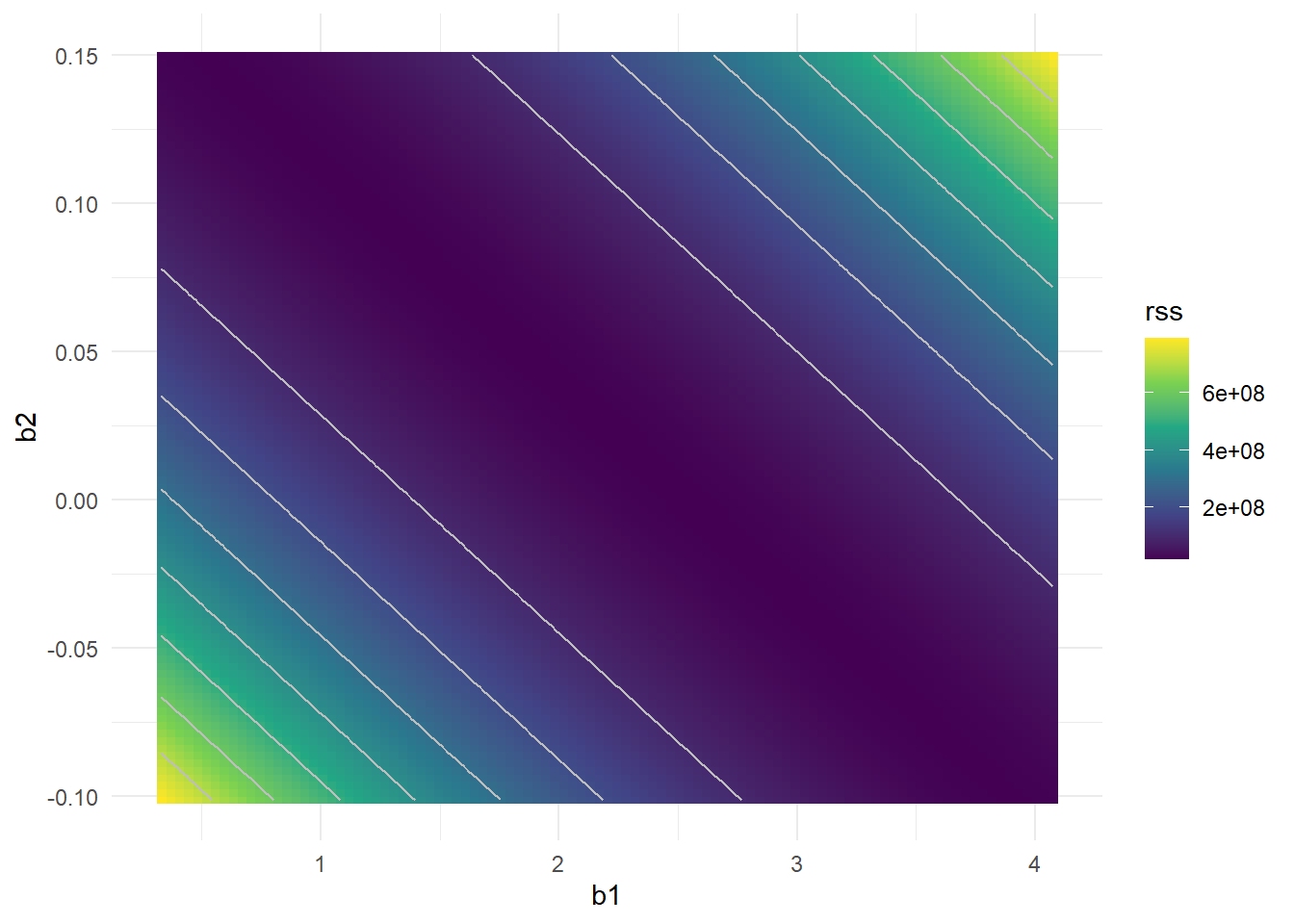
Interestingly, even though the limit and rating coefficients now have much more individual uncertainty, they will almost certainly lie somewhere in this contour valley. For example, we would not expect the true value of the limit and rating coefficients to be ???0.1 and 1 respectively, even though such a value is plausible for each coefficient individually.
Correlation Matrix
A simple way to detect collinearity is to look at the correlation matrix of the predictors. An element of this matrix that is large in absolute value indicates a pair of highly correlated variables, and therefore a collinearity problem in the data. Unfortunately, not all collinearity problems can be detected by inspection of the correlation matrix: it is possible for collinearity to exist between three or more variables even if no pair of variables has a particularly high correlation. We call this situation multicollinearity.2
|
|
| Income | Limit | Rating | Cards | Age | Education | Gender | Student | Married | Ethnicity | |
|---|---|---|---|---|---|---|---|---|---|---|
| Income | 1.00 | 0.79 | 0.79 | -0.02 | 0.18 | -0.03 | -0.01 | 0.02 | 0.04 | -0.03 |
| Limit | 0.79 | 1.00 | 1.00 | 0.01 | 0.10 | -0.02 | 0.01 | -0.01 | 0.03 | -0.02 |
| Rating | 0.79 | 1.00 | 1.00 | 0.05 | 0.10 | -0.03 | 0.01 | 0.00 | 0.04 | -0.02 |
| Cards | -0.02 | 0.01 | 0.05 | 1.00 | 0.04 | -0.05 | -0.02 | -0.03 | -0.01 | 0.00 |
| Age | 0.18 | 0.10 | 0.10 | 0.04 | 1.00 | 0.00 | 0.00 | -0.03 | -0.07 | -0.03 |
| Education | -0.03 | -0.02 | -0.03 | -0.05 | 0.00 | 1.00 | -0.01 | 0.07 | 0.05 | -0.03 |
| Gender | -0.01 | 0.01 | 0.01 | -0.02 | 0.00 | -0.01 | 1.00 | 0.06 | 0.01 | 0.00 |
| Student | 0.02 | -0.01 | 0.00 | -0.03 | -0.03 | 0.07 | 0.06 | 1.00 | -0.08 | -0.03 |
| Married | 0.04 | 0.03 | 0.04 | -0.01 | -0.07 | 0.05 | 0.01 | -0.08 | 1.00 | 0.06 |
| Ethnicity | -0.03 | -0.02 | -0.02 | 0.00 | -0.03 | -0.03 | 0.00 | -0.03 | 0.06 | 1.00 |
|
|
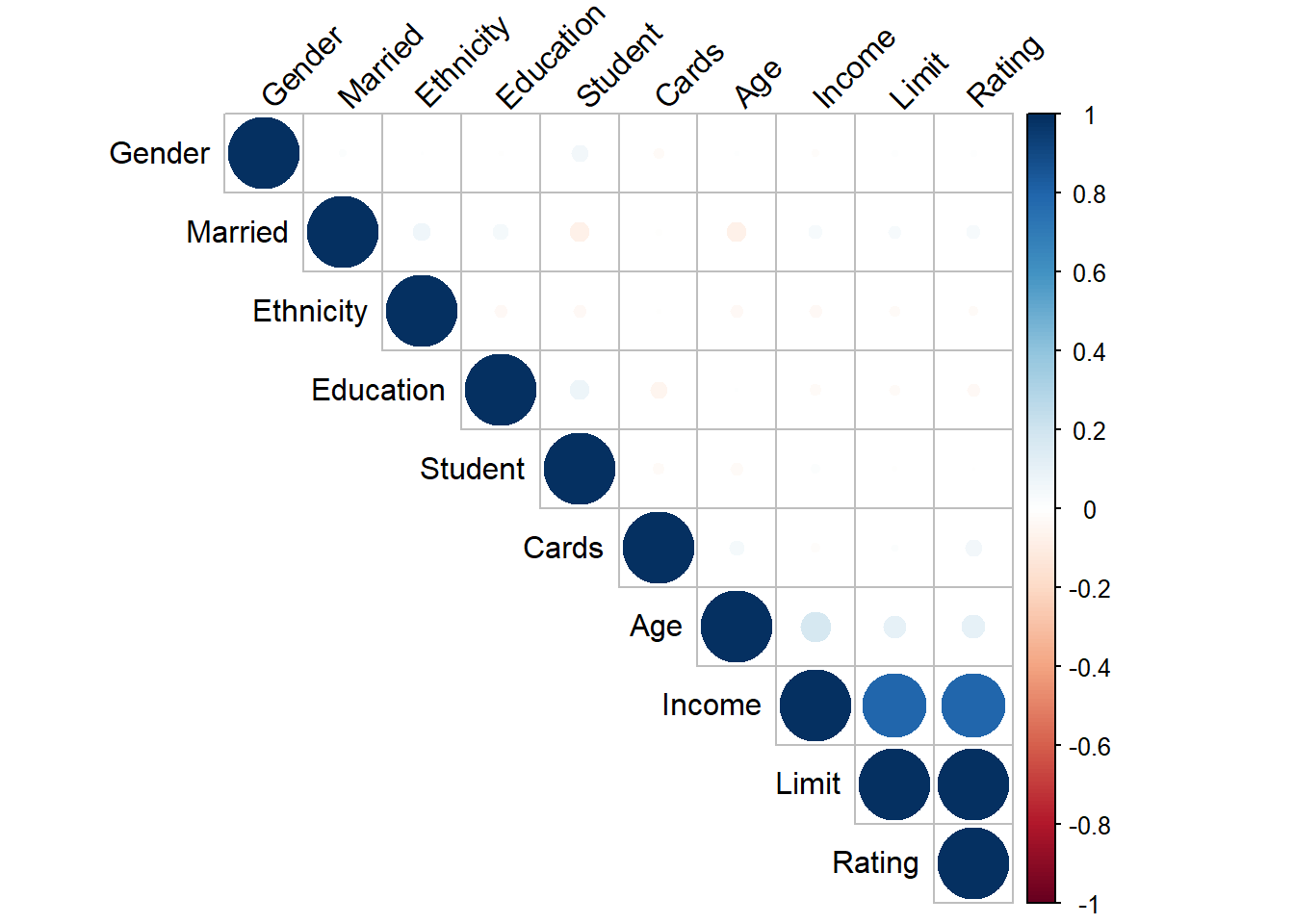
We see in the chart that income, limit and rating are highly correlated between, what is expected in term of finalcial credit.
Conclusion
When faced with the problem of collinearity, there are two simple solutions. The first is to drop one of the problematic variables from the regression. This can usually be done without much compromise to the regression fit, since the presence of collinearity implies that the information that this variable provides about the response is redundant in the presence of the other variables.
The second solution is to combine the collinear variables together into a single predictor. For instance, we might take the average of standardized versions of limit and rating in order to create a new variable that measures credit worthiness.
References
-
Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani. Introduction to Statistical Learning in R, p.99 ↩︎
-
Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani. Introduction to Statistical Learning in R, p.101 ↩︎