In this post, we’ll try to forecast my weight using Forecast and Facebook’s Prophet packages. We’ll see what is the performance from Facebook’s method in a simple case of forecast.
Recently, in the beginning of march, I went to a Nutritionist who recommended me to start a regime to lost some weight. As a good practice in these situations, short feedback cycles are essential to (re)build good habits, so I start to weigh myself almost daily, and record the values in a spreadsheet to follow my progress.
I kept the record until end of may, when my vacations started and I travel for three weeks, and now, at end of June, I restart to record my weight again. Between this time, I saw the Bruno Rodrigue’spost where he try to forecast his weight using the Forecast package, and I was inspired to do the same, but using my own data, and see how the Facebook’s Prophet package performs trying to predict my weight in the final of June using the data recorded between March and May.
1
2
3
4
5
6
7
8
9
10
#setuplibrary(googlesheets4)# I keep my records in a google spreadsheetlibrary(tibbletime)# We'll use tibble time and mice to fill the gap in the library(mice)# weighting recordslibrary(tsibble)# TS Tibble is a 'time aware tibble' to keep time series data library(lubridate)# lubridate to manipulate easly date-time info library(tidyverse)# tidyr, dplyr and magrittrlibrary(forecast)# package 'standard' to forecast time serieslibrary(prophet)# the 'facebook' method
Loading the dataset and filling the gaps
I weigh myself almost daily (but, in the weekends I’m usually away from home) and keep the weight records in a Google Spreadsheet, so let’s get the data set using the googlesheets package and fill the gap using mice package.
1
2
3
4
5
6
7
8
9
10
11
12
13
# download data from google spreadsheetsgs4_auth(email="gsposito@gmail.com")raw_data<-read_sheet("1P1q58DYs4Jy5cXKXCrdl11ru4Rop1Mu7r8fXEraCX9M")# handles date/weightraw_data%>%# the dataset has record for date, weigth, fat, select(1:2)%>%# water, muscle and bones, filtering first twomutate(Peso=Peso/10)%>%# to make it Kilogramsset_names(c("date","weight"))->measureshead(measures,10)%>%kable(align="c",bootstrap_options="striped",full_width=F)%>%kableExtra::kable_styling(font_size=11)
date
weight
2018-03-05
10.14
2018-03-06
10.15
2018-03-07
10.12
2018-03-08
10.06
2018-03-09
9.99
2018-03-10
9.98
2018-03-12
9.90
2018-03-13
9.94
2018-03-14
9.84
2018-03-15
9.82
We can see there is no data recorded at days 11, 16, 17 and 18 and go on. Also, there is a big gap in June.
Let’s separate the last two points, in June, from the remaining data, so we’ll have something like a “training” and a “test” data sets.
1
2
3
4
5
6
7
8
# taking the June measures as a "test" pointsweight.target<-measures%>%filter(date>=ymd(20180601))%>%mutate(date=as.Date(date))# and the previous as "training" points to be used in Forecast and Prophetmeasures<-measures%>%filter(date<ymd(20180601))
Let’s make the gaps in the “training” data set explicit, so we can fill’in them using mice.
Now, with “NA” explicit in the time series we can use [mice].
1
2
3
4
5
6
7
8
9
10
11
12
13
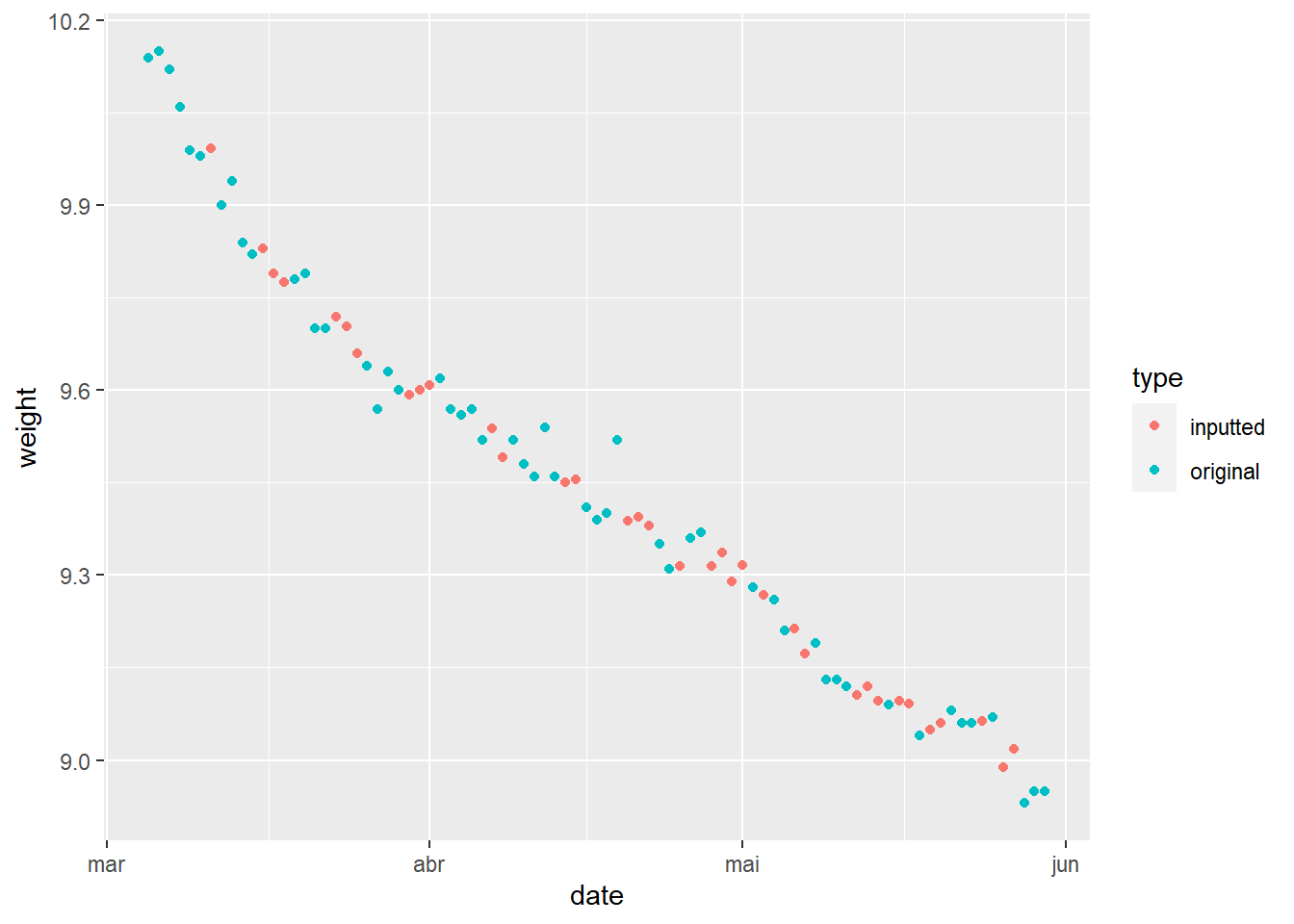
# complete valuesmeasures%>%mice(method="pmm",m=5,maxit=50,seed=42,printFlag=F)%>%# five imputation for NAmice::complete("long")%>%# fill the NAgroup_by(date)%>%# average them (5 points for missing data)summarise(weight=mean(weight))->measures_completed# compare original data and missing valuesmeasures_completed%>%inner_join(measures,by="date")%>%# join with original (with NA) datasetset_names(c("date","inputted","original"))%>%tidyr::gather(type,weight,-date)%>%# pivot-itggplot()+geom_point(aes(date,weight,color=type))
Well, the mice package did a remarkable job, the inputted values (red ones) seems like real measures, now with data set completed we convert it to a time series and use forecast to predict the weight behavior in June.
Forecasting with Forecast Package
The Forecast package implements ARIMA models for time series data. In statistics and econometrics, and in particular in time series analysis, an autoregressive integrated moving average (ARIMA) model is a generalization of an autoregressive moving average (ARMA) model. Both of these models are fitted to time series data either to better understand the data or to predict future points in the series (forecasting). (more on ARIMA)
Let’s use this model to forecast.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# models the time seriesmodel<-measures_completed%>%pull(weight)%>%# convert to a vectoras.ts()%>%# transform to a Time Serieauto.arima()# fit the model# make de predicion for 30 daysprediction<-model%>%forecast(h=31)%>%# forecast next 30 measuresas.tibble()%>%# covert to tibblemutate(date=max(measures_completed$date)+1:31)# add the dates# prediction datasethead(prediction)%>%kable()%>%kableExtra::kable_styling(font_size=11)
Point Forecast
Lo 80
Hi 80
Lo 95
Hi 95
date
8.928799
8.882932
8.974666
8.858651
8.998947
2018-05-31
8.914873
8.862890
8.966856
8.835372
8.994374
2018-06-01
8.900948
8.843496
8.958399
8.813083
8.988812
2018-06-02
8.887022
8.824579
8.949465
8.791524
8.982520
2018-06-03
8.873097
8.806033
8.940161
8.770531
8.975662
2018-06-04
8.859171
8.787785
8.930558
8.749995
8.968347
2018-06-05
1
2
3
4
5
6
7
8
9
10
11
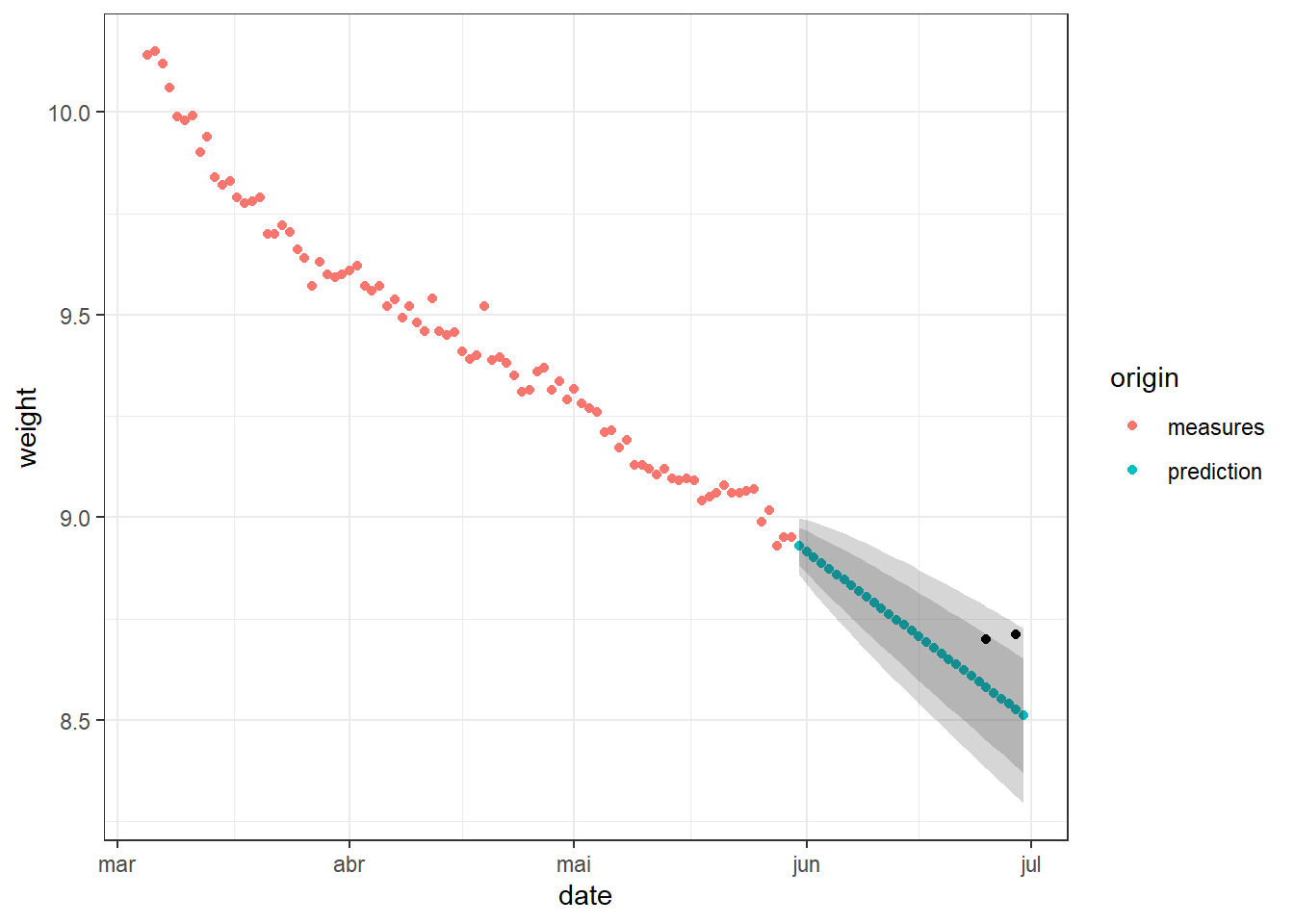
# plot to compare the prediction with the real valuesprediction%>%rename(weight=`Point Forecast`)%>%# rename the forecast columnmutate(origin="prediction")%>%# mark the data as 'prediction'bind_rows(measures_completed%>%mutate(origin="measures"))%>%# join with real dataggplot(aes(x=date))+geom_point(aes(y=weight,color=origin))+geom_ribbon(aes(ymin=`Lo 80`,ymax=`Hi 80`),alpha=0.2)+geom_ribbon(aes(ymin=`Lo 95`,ymax=`Hi 95`),alpha=0.2)+geom_point(data=weight.target,mapping=aes(date,weight))+theme_bw()
The Forecast package did a “OK” job, the first real measure are in the 80% certainty range and the second in the 95% range, what is, for predictions, a good job. But the model miss the two points, they are at the edge of the certainty interval.
1
2
3
4
5
6
7
# comparing the real and predicted valuesprediction%>%inner_join(weight.target,by="date")%>%select(date,`Lo 95`,forecast=`Point Forecast`,weight,`Hi 95`)%>%mutate(interval_size=`Hi 95`-`Lo 95`)%>%kable()%>%kableExtra::kable_styling(font_size=11)
date
Lo 95
forecast
weight
Hi 95
interval_size
2018-06-25
8.380875
8.580660
8.70
8.780446
0.3995711
2018-06-29
8.311620
8.524958
8.71
8.738296
0.4266767
Can the Facebook’s Prophet do a better job?
Prophet
The Facebook’s Prophet is a procedure for forecasting time series data based on an additive model where non-linear trends are fit with yearly, weekly, and daily seasonality, plus holiday effects. It works best with time series that have strong seasonal effects and several seasons of historical data. Prophet is robust to missing data and shifts in the trend, and typically handles outliers well.
Facebook implemented the procedure in R and Python and make it public in 2017, the package Prophet gives you access to it. If you want to know more about it, check this.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# by definition we need to pass a df with 2 columns "ds" (datestamp) and "y" (target var)measures_completed%>%set_names(c("ds","y"))%>%prophet()->pmodel# we use the model to make the predictionpmodel%>%make_future_dataframe(30)%>%predict(pmodel,.)->pprediction# what is the output formatpprediction%>%as.tibble()%>%glimpse()
As you see, the prophet’s prediction give us a lot of information, let’s check how it performed.
1
2
3
4
5
6
7
8
9
10
11
12
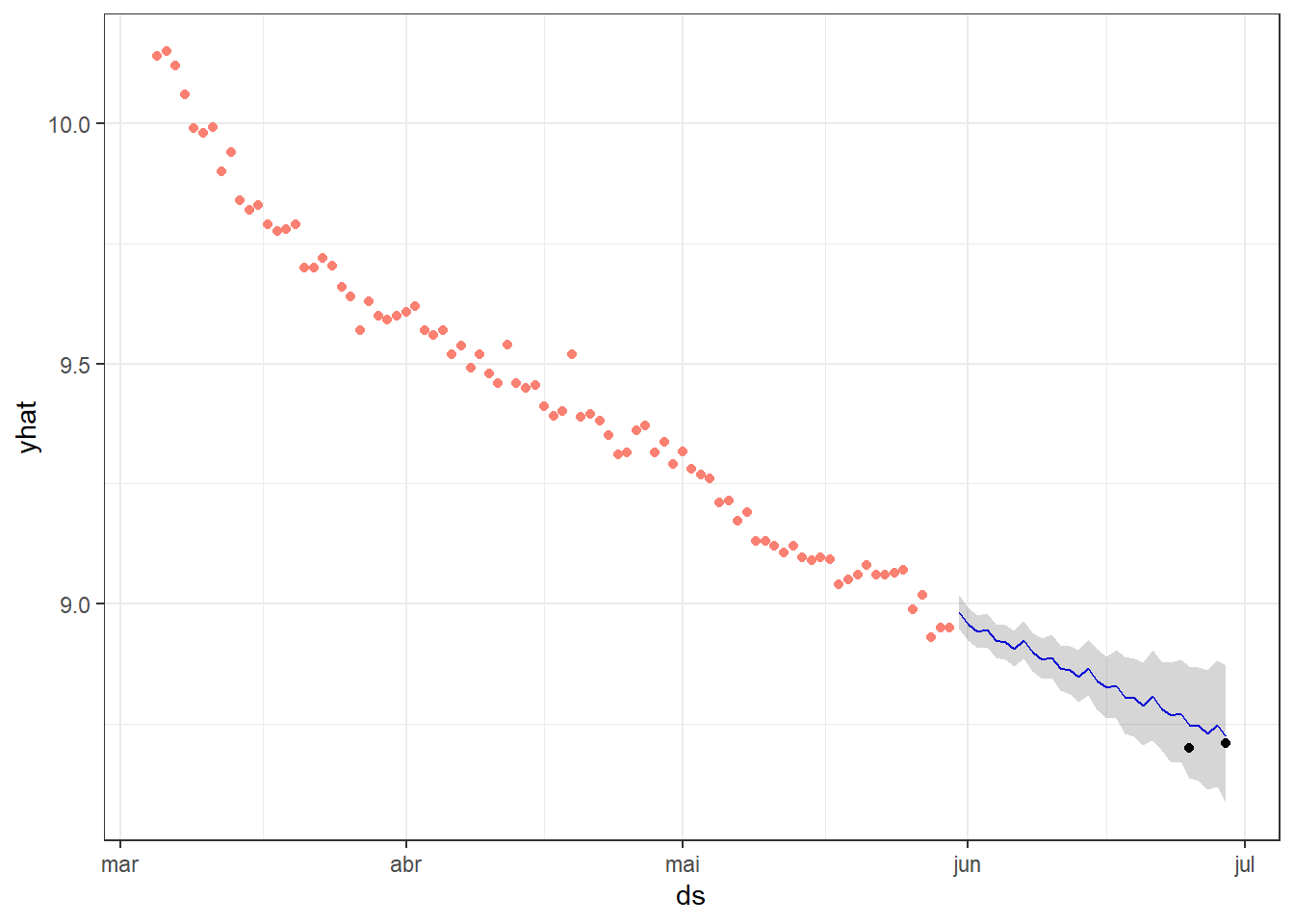
#plot the prediction against the targetpprediction%>%as.tibble()%>%mutate(ds=as_date(ds))%>%filter(ds>max(measures_completed$date))%>%select(ds,trend,yhat,yhat_lower,yhat_upper)%>%ggplot()+geom_line(aes(x=ds,y=yhat),color="blue")+geom_ribbon(aes(x=ds,ymin=yhat_lower,ymax=yhat_upper),alpha=0.2)+geom_point(data=measures_completed,aes(x=date,y=weight),color="salmon")+geom_point(data=weight.target,mapping=aes(x=date,y=weight),color="black")+theme_bw()
Wow, the prophet to an excellent job, the real measures are in the center of the range and the prediction values are close to it.
1
2
3
4
5
6
7
8
9
# checking the values in the June measurespprediction%>%as.tibble()%>%mutate(date=as_date(ds))%>%inner_join(weight.target,by="date")%>%select(date=ds,yhat_lower,yhat,weight,yhat_upper)%>%mutate(interval_size=yhat_upper-yhat_lower)%>%kable()%>%kableExtra::kable_styling(font_size=11)
date
yhat_lower
yhat
weight
yhat_upper
interval_size
2018-06-25
8.637765
8.748224
8.70
8.870323
0.2325575
2018-06-29
8.584754
8.723976
8.71
8.872009
0.2872546
As you saw, the prediction points made by prophet are remarkable close to the real values and also the size of certainty interval is very narrow, almost half forecast´s.
Of course, we just use these packages “out-of-the-box”, we didn’t tunning the Forecast parameters, maybe it can be a better job, but this don’t invalidate the results of Prophet.
The performance of the prophet was great in the test, for sure, the this package deserves another post in the future, to explore other features available.